Cyclical Learning Rates for Training Neural Networks
Research Topic
- Category (General): Deep Learning
- Category (Specific): Hyperparameters (Learning rate) Tuning
Paper summary
- Instead of monotonically decreasing the learning rate as in the traditional way, the author introduced a new method (called Cyclical Learning Rates) to control it, allowing the hyper-parameter to rise and fall systematically during training.
- CLR improves classification accuracy without tuning and does not require any computations.
- The author also showed a way to estimate the bounds for the learning rate to vary while training.
Explain Like I’m 5 (ELI5) 👶👶👶
Imagine you try to draw a picture, there are multiple ways to tackle this:
- You jump straight-in, drawing up to ~80-90% of the picture. However, to refine it, you have to slow down to finish the touches, which very tiring, so you might have to slow down much more until you finish it or abandon it midway. (~ Learning rate schedule)
- You start by drawing the layout, and then you calculate how much effort you should spend on each section. After you finish one, you reevaluate again and continue to draw until the picture is done. (~Adaptive learning rate)
- You start simple, draw a tree today, draw some more trees tomorrow, and draw a sun and a mountain the following day. The gist is that you start slow and progress over time until you reach a particular intensity. Then you slow down again to avoid burnout until you’re at the initial state (finish a cycle), you will restart the cycle again until the picture is done. (~Cyclical Learning Rates)
Issues addressed by the paper
- To train a deep neural network to convergence requires one to experiment with a variety of LR.
- There are already multiple solutions to this. These include learning rate scheduling (e.g., time-based decay, step decay, exponential decay), or adaptive learning rate (e.g., RMSProp, AdaGrad, AdaDelta, Adam), but there are still some drawbacks such as:
- Learning rate scheduling: Monotonically decreased learning rate, which later proved that it would not help the model escape from the saddle point.
- Adaptive learning rate: requires high computational cost.
Approach/Method
- Observation: increasing the learning rate might have a short term negative effect and yet achieve a longer-term beneficial effect. (since increasing the learning rate allows more rapid traversal of saddle point plateaus)
- Pick minimum (
base_lr) and maximum (max_lr) boundaries, and the learning rate will cyclically vary between these bounds.
-
For the cyclical function, triangular(Bartlett) window, parabolic(Welch) window, and sinusoidal(Hanning) window produced equivalent results, which led to adopting a triangular window thanks to its simplicity.
-
Other variations:
triangular: using triangular windowtriangular_2: same as triangular but after every cycle,max_lris halvedexp_range: each boundary value declines by exponential factor of current iterations.
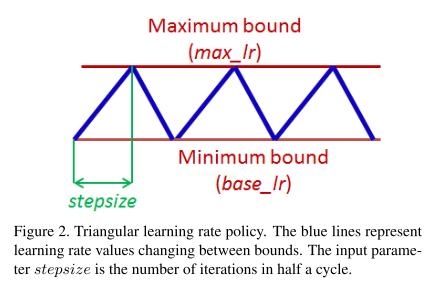
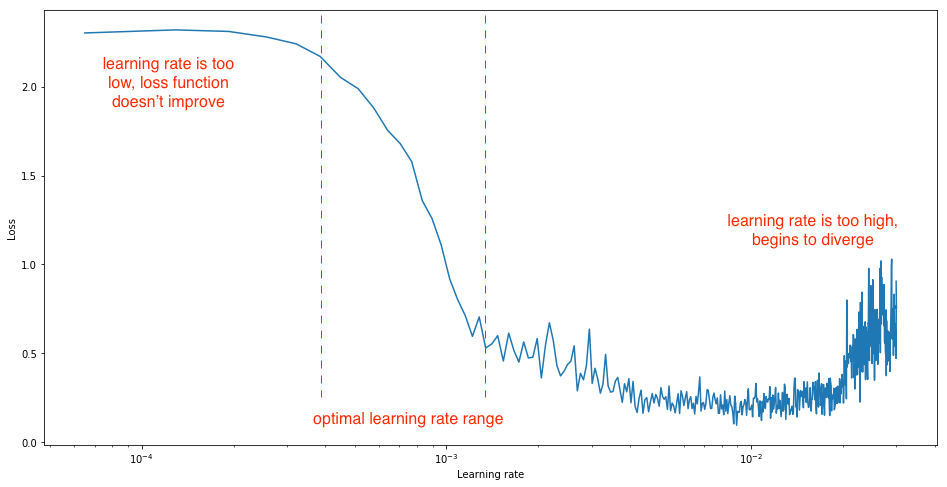
- How to find the bounds?
- Using “LR range test”:
- Run model for several epochs while letting the learning rate increase linearly between low and high LR values.
- Notice these 2 points:
- When accuracy starts to increase. ->
base_lr - When accuracy slows down, becomes ragged or falls down. ->
max_lr
- When accuracy starts to increase. ->
- Using “LR range test”:
Best practices
- Set
stepsizeto 2-10 times of #iterations/epoch. - Best to stop training at the end of the cycle (LR at
base_lrand the accuracy peaks)- -> Early stopping might not be good for CLR.
- Optimum learning rate is usually within a factor of two of the largest one that converges, and set
base_lr= \(\frac{1}{3}\) or \(\frac{1}{4}\) ofmax_lr.
Results
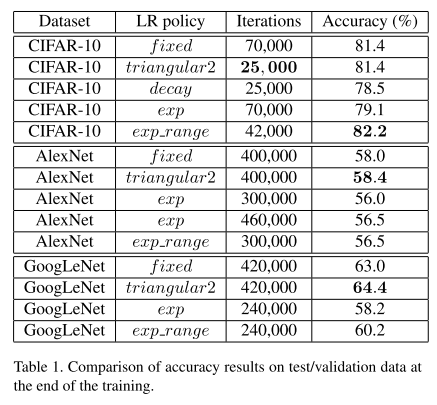
CLRhelps to model to converge much faster.Decay(monotonically decreasing LR)’s result provides evidence that both increasing and decreasing LR are essential.
Limitations
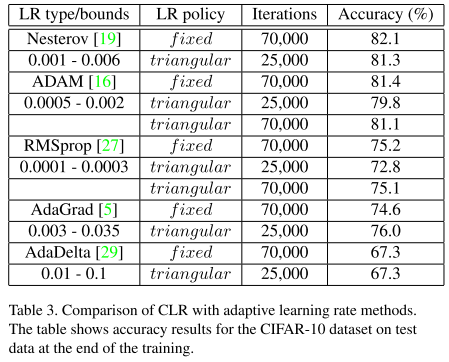
- When using with adaptive learning rate methods, the benefits from CLR are reduced.
Confusing aspects of the paper
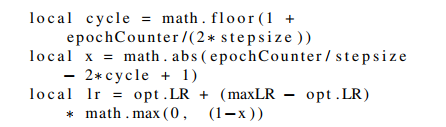
- The variables of the code weren’t explained clearly, so I redefine it here:
- 1 epoch: converted to #iterations (= training_size / batch_size).
- 1 cycle: LR goes from
base_lr->max_lr->base_lr. epochCounter: current #iterations (e.g: 1 epoch has 2000 iters, the model’s at epochs 1.5 =>epochCounter= 3000).stepsize: #iterations to reach 1/2 cycle.opt.LR: base lrcycle: which cycle the model’s currently in (1-2-…), always starts from 1 (first cycle).x: which part of the half-cycle, in range [0,1].lr: the updated lr, withtriangularmethod.
Conclusions
The author’s conclusions
- All experiments show similar or better accuracy performance when using CLR versus using a fixed learning rate, even though the performance drops at some of the learning rate values within this range.
Rating
Noice
My Conclusion
- This paper is straightforward, well-explained, so I highly recommend new DL-practitioners to try reading it.
- CLR is an impressive technique to control the learning rate. We should try this method when we started a new model or a new dataset, giving a lovely baseline for further optimization.
- CLR is also widely used by kagglers.
Paper implementation
Cyclical Learning Rates
triangularimplementation:
triangular_2implementation:
exp_rangeimplementation:
-
Plot:
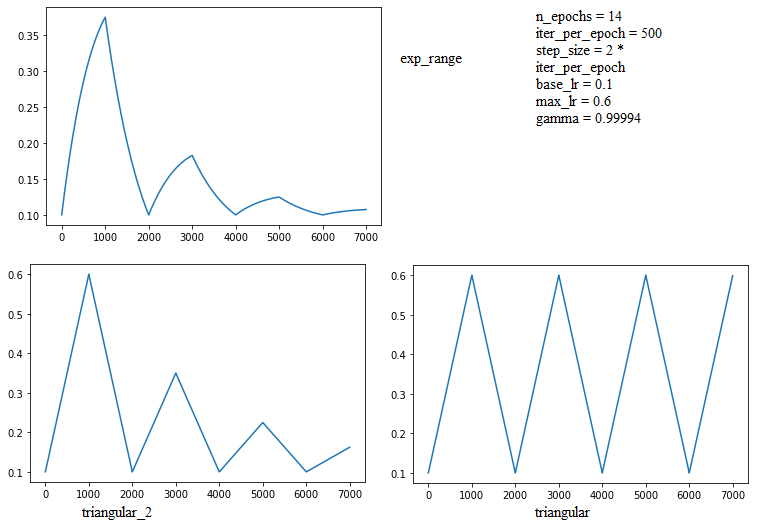
- Explaination for how x is calculated:
- \(raw\_x = \frac{current\_iteration}{step\_size}\): current cycle in term of half-cycles (floatting point)
- \(x’ = raw\_x - 2*cycle\): how many half-cycles left to complete this cycle
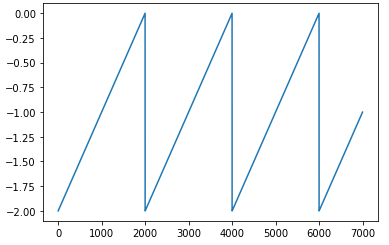
- \(x’ = x’ + 1\): Shift so that the function 0-centered on the y-axis, so that when we take absolute, we can achieve cycles.
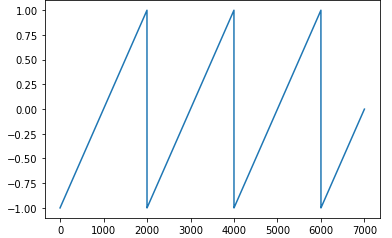
- \(raw\_x = \frac{current\_iteration}{step\_size}\): current cycle in term of half-cycles (floatting point)
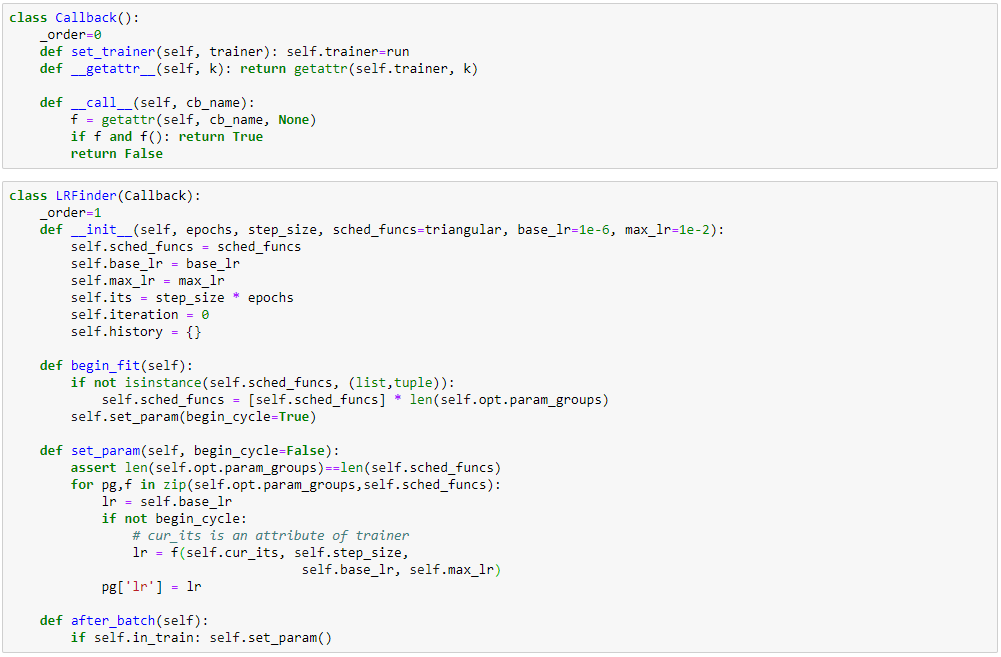
Learning Rate Finder
- An implementation of LRFinder using CLR using Callback (highly influenced by fastai):
Cited references and used images from:
- https://www.jeremyjordan.me/nn-learning-rate/
- https://github.com/bckenstler/CLR/